








Stéphane Déprès, coach Agile & Consultant expert chez inspearit, propose aux lecteurs de Solutions Numériques un article que se veut didactique et opérationnel pour toutes les DSI qui souhaitent se lancer dans des projets de « data thinking » (entre data science et design thinking).
Nick heudecker, analyste au Gartner estimait en novembre 2017 que le taux d’échec des projets big data était proche de 85 %. Bernard Marr, data scientist nous donne l’explication : une majorité des projets de data science échouent car les organisations surfant sur la vague du “hype big data” lancent des projets avec une logique « moi aussi » sans suffisamment réfléchir à une stratégie métier et au retour sur investissement et sans suffisamment impliquer les métiers et les utilisateurs finaux.
Et pourtant le machine learning et en particulier le deep learning promet de révolutionner les entreprises à tous les niveaux en leur apportant des avantages concurrentiels “différenciants”. Non seulement le machine learning permet l’aide à la prise de décision mais dans un futur proche, il pilotera probablement directement les processus métier et remplacera – du moins en partie – les opérateurs.
Derrière la notion de “hype big data” se cache un ensemble de paradigmes et d’outils permettant de stocker et traiter de très gros volume de données en parallèle avec scalabilité et tolérance aux fautes. Le machine learning est l’une de ces technologies d’intelligence artificielle qui permet d’apprendre à partir des données sans que les règles inférées ne soient explicitement programmées. D’autre part, le design thinking désigne cette approche de l’innovation basée sur un processus de co-créativité qui implique l’utilisateur final.
Pour revenir à notre problématique initiale, nous pouvons nous demander pourquoi le design thinking classique ne peut pas être utilisé dans le contexte d’un projet de data science afin d’en maximiser la valeur produite. En réalité, il est possible de l’utiliser à condition de l’envisager dans un contexte de Data Science. Nous nommerons cette nouvelle démarche le data thinking.
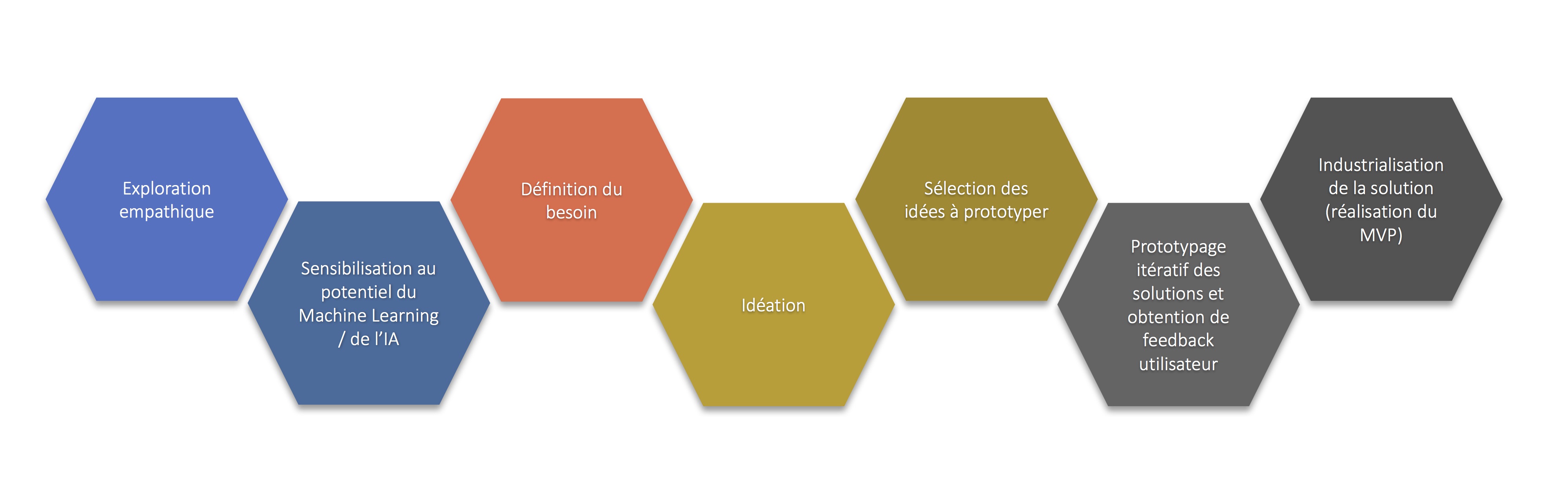
Le processus de data thinking suivant n’est pas forcément linéaire et plusieurs cycles peuvent être envisagés :
Etape 1 : l’exploration empathique
Une connaissance superficielle des usages ne suffit plus à créer la différence. L’exploration empathique – clé de voûte de cette démarche – consiste à observer et à interviewer des porteurs d’intérêt de manière à chercher à établir ce qu’ils font, pensent, ressentent, disent et quelles données ils manipulent. Lorsque l’on parle de données, on pense bien sûr aux données contenues dans les bases de données et les fichiers. Mais les actions, les décisions, l’ouïe, la vision voire le toucher et l’odorat sont également des sources de données.
Etape 2 : la sensibilisation au potentiel du machine learning / de l’IA
Cette sensibilisation des parties prenantes est un catalyseur de l’innovation pour l’étape d’idéation mais également pour l’étape de définition du besoin dans le sens ou un besoin non envisagé peut être mis en lumière par le potentiel.
Typiquement un data scientist présentera pendant cette étape les concepts et des exemples d’apprentissage supervisé et non supervisé.
Pour rappel, l’apprentissage supervisé permet à un algorithme d’apprendre à partir d’un jeu de données d’apprentissage – comme par exemple identifier la probabilité de départ d’un employé à partir de données RH ou l’origine ethnique d’un individu à partir de données ADN.
L’apprentissage non supervisé quant à lui permet d’identifier des structures dans les données sans nécessiter d’apprentissage sur un jeu de données. Par exemple identifier à partir du seul enregistrement des coordonnées GPS d’une voiture si le conducteur est le conducteur principal ou non.
Etape 3 : la définition du besoin
Cette étape consiste à identifier, synthétiser et prioriser les différents besoins. Des techniques de design thinking classiques comme les “Persona” et le parcours utilisateur (customer journey) peuvent être mis en œuvre durant cette étape.
Etape 4: l’idéation
Cette étape consiste à générer le maximum d’idées répondant au besoin en utilisant l’intelligence collective, en créant des ponts entre différents secteurs d’activité, en utilisant des techniques de brainstorming, mind mapping, sketching….
Pendant cette étape, tout est possible : aucune idée ne sera jugée folle, la liberté doit être totale. La présence d’un data scientist et du métier/des utilisateurs est indispensable.
Etape 5: la sélection des idées à prototyper
Dans cette étape, le data scientist rejette les idées clairement irréalisables et le métier/les utilisateurs identifient les idées qui apportent le plus de valeur (What Wows !). Positionner les idées dans un repère à deux dimensions (valeur, coût/difficulté) permet de prioriser les idées à prototyper.
Etape 6: prototypage itératif des solutions et obtention de feedbacks utilisateur
L’étape consiste à tester les idées rapidement afin d’évaluer ce qui marche et ce qui apporte le plus de valeur en collectant les avis des utilisateurs. Durant cette étape, privilégier des outils de prototypage rapide comme par exemple l’outil Orange Data Mining ou l’outil Dataiku DSS qui permettent de mettre en œuvre des solutions de Machine Learning avec une programmation visuelle. La phase la plus délicate étant sans doute le choix et la dérivation des features à partir des données de base et la constitution du jeu de données.
La phase de prototypage elle-même pourra être itérative afin d’obtenir un niveau de résultat convenable en réglant en particulier les problèmes d’underfitting et d’overfitting propre au Machine Learning.
Etape 7 : industrialisation de la solution
Si la valeur économique de la solution est avérée, il ne reste plus qu’à passer à la phase d’industrialisation en se concentrant dans un premier temps sur le MVP (Minimum Viable Product) et en collectant continuellement du feedback auprès du métier grâce à une approche Agile.





