- Optimiser les coûts du datacenter
- hyland-capabilities
- ppt-p10
- ppt-p10
Pour rester compétitifs face aux géants du Cloud, les opérateurs de datacenters doivent suivre les évolutions de chacune de leurs infrastructures et changer de culture très rapidement.
Rationalisation des coûts et globalisation des offres provoquent les méga-fusions actuelles. En diminuant le nombre d’acteurs, ces rapprochements vont inévitablement provoquer une bataille avec les géants du Cloud qui vont s’éloigner de la colocation pour opérer leurs propres bâtiments. « Dans un datacenter, raisonner petit ne fait pas de sens. Les petites salles et les petits boîtiers ne seront jamais aussi efficaces qu’un énorme bâtiment aux salles optimisées et à la consommation d’énergie maîtrisée. Plus l’aquarium est grand, plus il est stable », compare Fabien Gautier, Marketing Director, Equinix France, Spain and Portugal.

Quelle que soit la taille de l’aquarium, la voracité de certains poissons ne fait aucun doute : fin octobre 2019, l’américain Digital Realty annonçait son intention d’avaler le hollandais Interxion – le numéro deux Européen derrière Equinix -, par échange d’actions à hauteur de 8,4 milliards de dollars. Il compte ainsi contrôler 70% du marché Européen en 2020, via 53 sites et 13 métropoles dont Paris, Marseille, Francfort et Amsterdam.
Le Vieux Continent conserve un potentiel de croissance colossal, ce qui explique l’appétit actuel des géants mondiaux : « Près de 70 % des ressources IT résident encore hors d’un datacenter en France. Pourtant, ces ressources sont toutes légitimes à y aller. »
Le groupe Engie témoigne volontiers de l’intérêt des grands bâtiments high tech, directement raccordés à 19 de ses fournisseurs via plus de 200 liaisons à haut débit et latence réduite.
La notion d’écosystème devient attractive pour les multinationales, les opérateurs traditionnels et les prestataires de services managés. Chacun gagne à placer ses serveurs à proximité de ceux de co-locataires prestigieux, géants du Cloud inclus : « Plus de 150 opérateurs ont financé le génie civil pour rejoindre nos campus. La présence de 950 clients sur 60 000 m² exploitables est très rentable pour un opérateur : il est certain d’y trouver de nombreux clients », confirme Fabien Gautier.
« Dans un datacenter, raisonner petit ne fait pas de sens.
Les petites salles et les petits boîtiers ne seront jamais aussi efficaces qu’un énorme bâtiment. »
Fabien Gautier
Lisser les coûts d’infrastructure
« Les grands datacenters jouent sur les effets de concentration pour réduire leurs coûts », nuance Sami Slim, Deputy Director du Japonais Telehouse qui sert 500 clients en France à partir de trois datacenters. Il classe volontiers les coûts d’exploitation du site dans l’ordre suivant : coûts d’infrastructures, coûts humains et coûts d’énergie.

L’externalisation vers de grands sites de plusieurs dizaines de MW permet de lisser les investissements en groupes froids, groupes électrogènes et onduleurs. Le facteur humain, souvent négligé, se compose des gardiens de sécurité présents en permanence et du personnel de maintenance : « il faut intervenir le plus rapidement possible en cas d’incident, avec des compétences proches du datacenter, un haut niveau de réactivité et une bonne connaissance des installations. Les premières causes de pannes sont le manque de maintenance des équipements, les procédures non respectées et les fuites électriques. Quant au coût de l’électricité, il augmente en France, car le pays investit dans les énergies vertes et cela a un impact direct sur l’exploitation du datacenter ».
Les mêmes contraintes pèsent sur le centre de données d’entreprise dont les services doivent être disponibles en 24/7. D’où la location plus fréquente de services métiers, l’externalisation croissante d’espaces de stockage, de traitements et de connectivité auprès d’hébergeurs locaux, de sites de colocation ou d’opérateurs Cloud public.
Sami Slim note toutefois une nouvelle tendance, depuis dix ans, vers le datacenter éclaté : « Nos clients dédient un datacenter à chaque partie – traitements, stockage et réseaux – pour des raisons pragmatiques de coûts et de rationalisation. Ils mutualisent des serveurs dans le Cloud, loués à la minute, et conservent une partie de leur stockage critique chez nous. Les points de présence réseaux correspondent, pour leur part, à des enjeux de sécurité et de performances d’accès ».

Prévoir des extensions modulaires
L’outsourcing prend bel et bien plusieurs formes. « Nous sommes les mains et et les yeux de nos clients. Ce qui différencie notre datacenter, c’est la fourniture de services d’ingénierie, de support et l’expertise technique délivrée sur place », signale Yohann Berhouc, directeur général de Cyrès. En deux décennies, les métiers de la PME tourangelle de 45 salariés ont évolué du conseil technique aux infrastructures spécifiques à demeure, puis à l’accompagnement des clients vers le Cloud computing (AWS, MS-Azure), l’approche DevOps, les services big data et l’intelligence artificielle.
Présente à Tours et à Paris, Cyrès manquait d’espace en centre-ville pour héberger de nouveaux serveurs. La direction a alors fait le pari de construire son propre datacenter, à Tours Nord, dans un ancien bâtiment frigorifique réhabilité, étape par étape : « La première partie de 35 baies est pratiquement achevée offrant 300 m² d’espace utile pour l’informatique sur un bâtiment de 700 m². Nous étudions une seconde puis une troisième tranche pour accueillir 40 nouvelles baies. L’approche modulaire permet de monter en capacité, dès l’origine, avec des coûts progressifs. Alimentation électrique, refroidissement, supervision, système de lutte contre l’incendie, toutes les infrastructures sont conçues de façon modulaire. »

L’optimisation financière du datacenter s’inscrit dans un contexte de performances croissantes sur un espace au sol, certes évolutif, mais néanmoins contraint. Or, les équipements et compétences informatiques nécessaires à l’hébergement des services clients évoluent en permanence : « Il faut adapter les serveurs et les baies de stockage aux besoins de calculs et à la volumétrie croissante des données. Nous investissons dans des machines multiprocesseurs, des disques SSD NVMe pour optimiser les flux de transfert, et des cartes graphiques (GPU) pour les traitements d’IA. L’approche DevOps apporte l’agilité, sans contrainte sur le matériel. Nos architectures de virtualisation accueillent les outils d’automatisation (GitLab, Kubernetes, Docker, etc.). En revanche, la R&D doit s’adapter à ce changement de culture, monter en compétences régulièrement précise Marc Lafleuriel, directeur Exploitation et Sécurité de Cyrès.
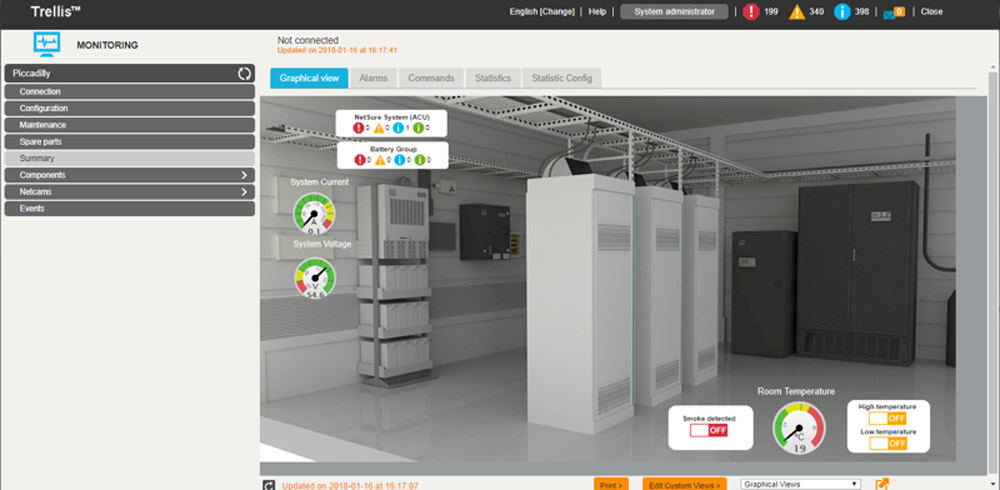
Les opérations de maintenance s’effectuent à chaud, dès que possible, pour limiter des arrêts de production particulièrement coûteux. « Notre datacenter de Tier 3 reçoit des équipements tous redondés à charge équivalente. Pour garantir une haute disponibilité à nos clients, on ne doit pas l’arrêter. Et pour que la maintenance soit transparente pour nos clients, nous devons trouver des solutions techniques et planifier chaque intervention en cohérence avec les préconisations des constructeurs, mener des tests trimestriels ou semestriels avec des mainteneurs certifiés », poursuit-il. Selon le refroidissement retenu, il convient de surveiller la facture d’énergie et aussi la facture d’eau. Il faut également anticiper les fluctuations de coûts, prévient le directeur général. Le site a récemment investi dans une trentaine de sondes de température pour surveiller au plus près la dissipation des équipements, réagir en cas de dysfonctionnement ou de déviation anormale.
Contrôles et entretiens réguliers
Dans le datacenter, 52 % des coûts d’énergie consommée sont imputables à l’infrastructure informatique – serveurs, baies de stockage et commutateurs réseau inclus. Les 48 % restants se répartissent dans les équipements de refroidissement des racks (38 %) et dans la distribution continue d’énergie, tableaux électriques et onduleurs inclus (10 %). Ces chiffres désignent d’emblée deux grands postes d’économies possibles dans le centre de données.

« Le refroidissement et l’alimentation en énergie présentent des phases de maintenance et un cycle de renouvellement distincts, observe Séverine Hanauer, directrice des ventes datacenters et télécommunications de Vertiv France. Une règle d’or consiste à effectuer un contrôle trimestriel du cooling et un contrôle semestriel de la distribution d’énergie. La courbe de fiabilité des onduleurs baisse après dix ans car leurs composants vieillissent. Les batteries ont une longévité variable, de 3 à 5 ans en entrée de gamme, jusqu’à 12 à 15 ans en haut de gamme. »
L’arrêt de production reste la bête noire de tout opérateur de datacenter. Pour l’éviter, les contrôles réguliers vont du simple examen à l’oeil nu jusqu’au système de monitoring avancé, de l’armoire électrique jusqu’aux circuits complets. Il s’agit d’anticiper la dégradation éventuelle d’un équipement pour procéder à son remplacement avant sa panne. « Un capteur est placé sur chaque bloc de batterie d’onduleur. Des tests d’injection de courant sont pratiqués pour simuler son vieillissement et pour anticiper une chute de performances. On peut ainsi prévoir, sans arrêt de production et sans perte d’autonomie, l’échange d’un ou de deux blocs. Changés à temps, les blocs en passe d’être défectueux ne provoquent aucune détérioration », explique Séverine Hanauer.
De même, au niveau du refroidissement, un système de sondes de détection évite l’arrêt de production, tandis que le changement régulier des filtres épargne l’encrassement fatal. Ces mesures, et bien d’autres, participent de l’efficacité énergétique du datacenter.

Benoit Matet, le directeur marketing en charge des datacenters chez Legrand, voit comme une nécessité croissante la maintenance prédictive à mesure que le nombre d’interventions à distance augmente : « Nos clients doivent gérer davantage de datacenters, dans plusieurs endroits parfois exigus, avec l’émergence des réseaux 5G. Dans un contexte de déploiement de micro-centres, à grande échelle, la supervision et la maintenance à distance des installations deviennent cruciales », souligne-t-il.
L’edge computing va accélérer cette tendance, les organisations repensant la distribution de leurs traitements et révisant leur télémaintenance. « Savoir qui accède au rack, et comment, devient de plus en plus important. En utilisant un réseau de PDU intelligents et des armoires aux poignées connectées, nous pouvons vérifier qui manipule chaque équipement, puis proposer une supervision locale ou à distance et gérer tous ces événements dans le Cloud », poursuit-il.
« Dans un contexte de déploiement de micro-centres, à grande échelle, la supervision et la maintenance à distance des installations deviennent cruciales. »
Benoit Matet
Gagner en autonomie
L’Intelligence Artificielle et la réalité augmentée tentent aussi de transformer la maintenance du datacenter. L’IA aide le technicien de maintenance à comprendre les infrastructures électriques, mais aussi à réduire le nombre d’alarmes qui peuvent encore le submerger.
« Certains clients nous demandent de gérer pour eux leurs infrastructures. Nous exploitons alors nos logiciels et constatons que l’on peut réduire de 54 % le nombre d’alarmes, tout en conservant un niveau suffisant d’informations. Grâce à l’IA, les alarmes deviennent prédictives : on peut préciser que, d’ici à trois mois, il faudra remplacer tel ou tel équipement. Cela laisse du temps aux équipes internes pour s’organiser », précise Kevin Brown, directeur technique de Schneider Electric.

Dans le datacenter, l’anticipation devient un gage d’autonomie. L’offre EcoStruxure de Schneider associe la réalité augmentée à des services Cloud diffusant la connaissance des circuits électriques et révélant précisément au technicien de maintenance ses prochaines interventions. En lien avec un ingénieur distant ou bien guidé par un tutoriel, le technicien sur site obtient des informations contextuelles et en temps réel sur sa tablette. Il peut vérifier le schéma électrique d’une armoire, sans même l’ouvrir, comprendre le rôle de chaque module et visualiser la chaîne d’équipements alimentée. Des maladresses et des interruptions de services non planifiées sont ainsi évitées lors des interventions de maintenance. La solution HyperFlex at the Edge – conçue avec Cisco – procure des fonctions de supervision et de maintenance à distance en lien avec les services Cloud EcoStruxure IT Expert et IT advisor pour accélérer le déploiement, la configuration et la mise en service de fermes de serveurs.
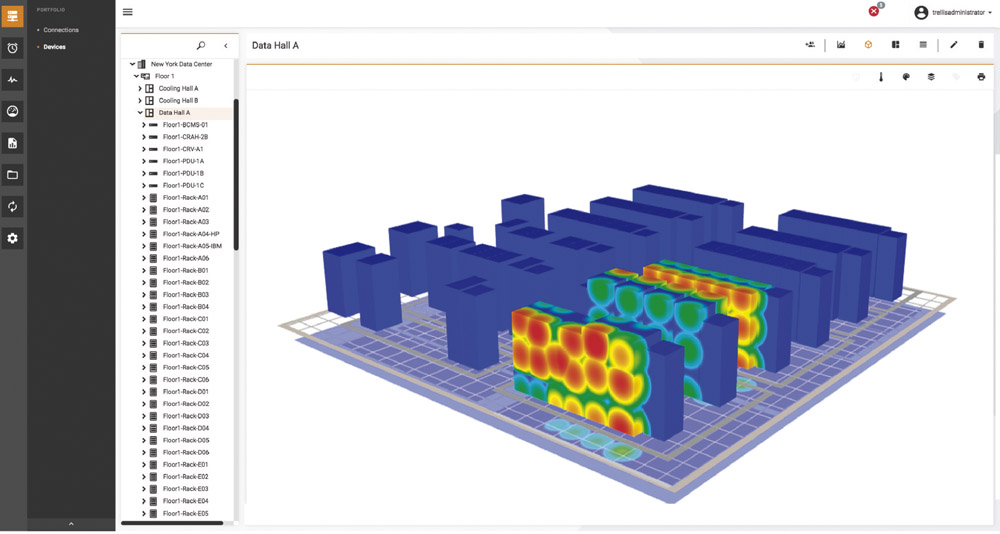
Surveiller les coûts d’énergie
Le centre de données concentre les besoins de calculs et de stockage pour un nombre croissant d’usages, d’utilisateurs et d’objets connectés. Comment réduire les coûts d’énergie tandis que les demandes en puissance de traitement ne cessent d’augmenter ?
Des équipements de plus haute densité, convergés ou hyper-convergés, rejoignent parfois les baies. « La densité informatique est de plus en plus élevée depuis quelques années. Le Cloud ne fait qu’accélérer ce mouvement. Jusqu’à six ans en arrière, cette densité IT était de 2 à 3 KW par m². A présent, les baies destinées aux applications Cloud requièrent 8 à 12 KW par m² », compare Séverine Hanauer. Destinés à l’hébergement des plus puissants ordinateurs des centres de recherche, les bandeaux de prises (jusqu’à 63 Ampères en triphasé chez Vertiv) datent de quinze ans déjà. Les serveurs HPC nécessitaient alors jusqu’à 40 KW par baie, soit le triple du standard actuel. En parallèle, l’architecture du système de refroidissement a dû s’adapter : « des couloirs ont fermé les allées chaudes et froides, permettant d’avoir plus de densité dans chaque baie avec une climatisation correcte. Simultanément, l’urbanisation de la salle a évité la surchauffe. »
La standardisation reste le mot d’ordre des grands prestataires Cloud. Plutôt que de miser sur une redondance complète, des alimentations d’énergie jusqu’aux équipements IT, ils multiplient les boîtiers économiques et standards dans leur datacenters, afin de rendre les sites eux-mêmes redondants les uns des autres : « Avec une architecture simple et bien connue, on gagne du temps et de l’argent et on évite des erreurs d’exploitation. Les géants de la colocation ont tendance à faire des systèmes hyperscales ; pour héberger les GAFAM et les dissuader de créer leurs propres centres, ils déploient rapidement leurs modèles d’infrastructures sur plusieurs continents », explique Séverine Hanauer. Ce design global fait largement appel à l’open innovation, à l’open software et à l’open hardware. Il impacte progressivement les choix des hébergeurs de proximité, et jusqu’à l’architecture même des bâtiments intelligents.